Shellcode: PEB i adres bazowy modułu kernel32.dll
• tech • 2919 słów • 14 minut czytania
Ta notatka jest częścią serii Shellcode: moje eksperymenty. Zapoznaj się z pozostałymi wpisami.
Pisząc jakieś shellkody lub inne tego typu paskudztwa napotyka się na problem interakcji z systemem lub jego API. Aby cokolwiek zrobić sensownego wymagany jest dostęp do kilku kluczowych funkcji znajdujących się w kernel32.dll, będących niejako kluczem do świata systemu. Takimi funkcjami są oczywiście LoadLibrary/GetModuleHandle, GetProcAddress, itp… Mając dostęp do tych funkcji możemy zrobić praktycznie wszystko i wykorzystać dowolny kod z innych modułów.
Nawet jeśli chce się wstrzyknąć tylko dll-kę importującą niezbędne i używane przez siebie rzeczy, to wymagany jest jakiś sensowny kod loadera, który także musi zostać wstrzyknięty do procesu. A ten loader jakimś cudem musi znać adres bazowy modułu kernel32 i offset do funkcji LoadLibrary, aby móc bezproblemowo załadować wstrzykiwany moduł do danego procesu.
O ile w czasach pre-Vista/Win7 i pre-ASLR, kiedy to moduły systemowe zawsze ładowane był w to samo miejsce w przestrzeni adresowej procesu, albo były randomizowane per reboot systemu, to adresy tych samych funkcji w różnych procesach były takie same. W takich wypadach wystarczyło, aby to caller (wstrzykujący) pobrał standardowymi metodami adres do danej funkcji z własnej przestrzeni i taki użył we wstrzykiwanym kodzie.
Czasy się zmieniały, dodawane nowe rozwiązania i zabezpieczenia miały teoretycznie na celu ukrócić takie zabawy. Ale w praktyce to za wiele się nie zmieniło, no może prócz potrzeby stworzenia większego fragmentu kodu ;)
Istnieje kilka metod determinacji adresu bazowego (ImageBase) pod którym w pamięci znajduje się kod modułu. Najbardziej popularnym sposobem jest skorzystanie z danych zawartych w strukturze PEB procesu. Można tam znaleźć pełną listę załadowanych do przestrzeni adresowej procesu modułów.
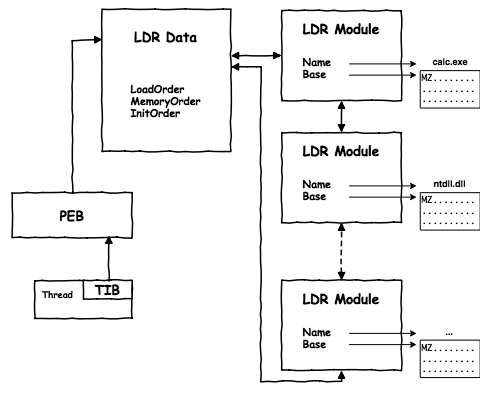
Dane te zawarte są w strukturze PEB_LDR_DATA używane przez funkcje loadera (Ldr*) w ntdll.
0:003> dt _PEB
ntdll!_PEB
...
+0x00c Ldr : Ptr32 _PEB_LDR_DATA
...
0:003> dt _PEB_LDR_DATA
ntdll!_PEB_LDR_DATA
+0x000 Length : Uint4B
+0x004 Initialized : UChar
+0x008 SsHandle : Ptr32 Void
+0x00c InLoadOrderModuleList : _LIST_ENTRY
+0x014 InMemoryOrderModuleList : _LIST_ENTRY
+0x01c InInitializationOrderModuleList : _LIST_ENTRY
+0x024 EntryInProgress : Ptr32 Void
+0x028 ShutdownInProgress : UChar
+0x02c ShutdownThreadId : Ptr32 Void
Istotne są tutaj dwukierunkowe listy LIST_ENTRY, zawierające, w odpowiedniej kolejności, odwołania (wskaźniki) do danych modułu opisanych strukturą LDR_MODULE (_windbg _widzi je jako LDR_DATA_TABLE_ENTRY).
0:003> dt _LDR_DATA_TABLE_ENTRY
ntdll!_LDR_DATA_TABLE_ENTRY
+0x000 InLoadOrderLinks : _LIST_ENTRY
+0x008 InMemoryOrderLinks : _LIST_ENTRY
+0x010 InInitializationOrderLinks : _LIST_ENTRY
+0x018 DllBase : Ptr32 Void
+0x01c EntryPoint : Ptr32 Void
+0x020 SizeOfImage : Uint4B
+0x024 FullDllName : _UNICODE_STRING
+0x02c BaseDllName : _UNICODE_STRING
+0x034 Flags : Uint4B
+0x038 LoadCount : Uint2B
+0x03a TlsIndex : Uint2B
+0x03c HashLinks : _LIST_ENTRY
+0x03c SectionPointer : Ptr32 Void
+0x040 CheckSum : Uint4B
+0x044 TimeDateStamp : Uint4B
+0x044 LoadedImports : Ptr32 Void
+0x048 EntryPointActivationContext : Ptr32 _ACTIVATION_CONTEXT
+0x04c PatchInformation : Ptr32 Void
+0x050 ForwarderLinks : _LIST_ENTRY
+0x058 ServiceTagLinks : _LIST_ENTRY
+0x060 StaticLinks : _LIST_ENTRY
+0x068 ContextInformation : Ptr32 Void
+0x06c OriginalBase : Uint4B
+0x070 LoadTime : _LARGE_INTEGER
Do którejś wersji (bodajże XP/Vista) niektóre (interesujące) systemowe moduły były ładowane w takiej samej kolejności, czyli były dostępne pod tym samym offsetem (indeksem) na liście. Wygaldało to mniej więcej tak:
; XP/pre-Win7
LoadOrder: proc, ntdll, kernel32, ...
MemoryOrder: proc, ntdll, kernel32, ...
InitOrder: ntdll, kernel32, ...
I z tego faktu korzystało dosyć dużo kodu. W 7-mce pojawił się kernelbase.dll, doszło do przetasowań i trochę się namieszało. Ciekawy jestem jak to wygląda pod tym właśnie systemem. Sprawdźmy na 32-bitowym Kalkulatorze ;)
0:003> !peb
PEB at 7efde000
...
Ldr.Initialized: Yes
Ldr.InInitializationOrderModuleList: 005c53d8 . 005e97b0
Ldr.InLoadOrderModuleList: 005c5348 . 005e97a0
Ldr.InMemoryOrderModuleList: 005c5350 . 005e97a8
Base TimeStamp Module
b60000 4ce7979d Nov 20 10:40:45 2010 C:\Windows\SysWOW64\calc.exe
77cf0000 58bf8715 Mar 08 05:22:45 2017 C:\Windows\SysWOW64\ntdll.dll
75690000 58bf87ba Mar 08 05:25:30 2017 C:\Windows\syswow64\kernel32.dll
77420000 58bf87bb Mar 08 05:25:31 2017 C:\Windows\syswow64\KERNELBASE.dll
...
Korzystając z makra !list można w windbg “przelecieć” po liście LIST_ENTRY. Trzeba pamiętać, że poszczególne elementy listy wskazują docelowo na “swojego” rodzaju listę zawartą w strukturze LDR_DATA_TABLE_ENTRY, dlatego trzeba odliczyć offset, aby dostać się na początek danych tejże struktury.
Początek listy InLoadOrderModuleList zawiera moduły:
0:003> !list -t ntdll!_LIST_ENTRY.Flink -x "dt _LDR_DATA_TABLE_ENTRY @$extret" 005c5348
ntdll!_LDR_DATA_TABLE_ENTRY
...
+0x024 FullDllName : _UNICODE_STRING "C:\Windows\SysWOW64\calc.exe"
+0x02c BaseDllName : _UNICODE_STRING "calc.exe"
...
ntdll!_LDR_DATA_TABLE_ENTRY
...
+0x024 FullDllName : _UNICODE_STRING "C:\Windows\SysWOW64\ntdll.dll"
+0x02c BaseDllName : _UNICODE_STRING "ntdll.dll"
...
ntdll!_LDR_DATA_TABLE_ENTRY
...
+0x024 FullDllName : _UNICODE_STRING "C:\Windows\syswow64\kernel32.dll"
+0x02c BaseDllName : _UNICODE_STRING "kernel32.dll"
...
ntdll!_LDR_DATA_TABLE_ENTRY
...
+0x024 FullDllName : _UNICODE_STRING "C:\Windows\syswow64\KERNELBASE.dll"
+0x02c BaseDllName : _UNICODE_STRING "KERNELBASE.dll"
...
Lista InMemoryOrderModuleList:
0:003> !list -t ntdll!_LIST_ENTRY.Flink -x "dt _LDR_DATA_TABLE_ENTRY @$extret-8" 005c5350
...
+0x02c BaseDllName : _UNICODE_STRING "calc.exe"
...
+0x02c BaseDllName : _UNICODE_STRING "ntdll.dll"
...
+0x02c BaseDllName : _UNICODE_STRING "kernel32.dll"
...
+0x02c BaseDllName : _UNICODE_STRING "KERNELBASE.dll"
...
Lista InInitializationOrderModuleList:
0:003> !list -t ntdll!_LIST_ENTRY.Flink -x "dt _LDR_DATA_TABLE_ENTRY @$extret-10" 005c53d8
...
+0x02c BaseDllName : _UNICODE_STRING "ntdll.dll"
...
+0x02c BaseDllName : _UNICODE_STRING "KERNELBASE.dll"
...
+0x02c BaseDllName : _UNICODE_STRING "kernel32.dll"
...
Podobnie wygląda to w 64-bitowej wersji systemu.
Aby upewnić się w jakiej kolejności ładowane są te moduły, należy zerknąć do kodu inicjalizującego proces w user-space. Dzieje się to w LdrpInitializeProcess (ntdll.dll), tam można znaleźć ciekawe fragmenty kodu przedstawione poniżej. Wynika z nich, że najpierw tworzona i wypełniana jest struktura LDR_DATA_TABLE_ENTRY dla bieżącego procesu i za pomocą funkcji LdrpInsertDataTableEntry dodawana jest do listy InLoadOrderModuleList i InMemoryOrderModuleList. Nastepnie to samo dzieje się dla znajdującego się już w pamięci modułu ntdll. A nieco później ładowane są standardowymi funkcjami, moduły kernel32 i kernelbase.
; UNICODE_STRING defs for module names in _LdrpInitializeProcess@8 body
...
.text:7DEB66FC _NtDllName dw 12h
.text:7DEB66FE dw 14h
.text:7DEB6700 off_7DEB6700 dd offset aNtdll_dll_0 ; "ntdll.dll"
...
.text:7DEB670C word_7DEB670C dw 18h
.text:7DEB670E dw 1Ah
.text:7DEB6710 dd offset aKernel32_dll ; "kernel32.dll"
...
.text:7DEF14C0 word_7DEF14C0 dw 1Ch
.text:7DEF14C2 dw 1Eh
.text:7DEF14C4 dd offset aKernelbase_dll ; "kernelbase.dll"
...
; create and insert LDR_MODULE for proc
.text:7DEB6419 call _LdrpAllocateDataTableEntry@4 ; LdrpAllocateDataTableEntry(x)
.text:7DEB641E mov _LdrpImageEntry, eax
...
.text:7DEB64DA push eax
.text:7DEB64DB mov [eax+30h], ecx ; LDR_DATA_TABLE_ENTRY.BaseDllName.Buffer
.text:7DEB64DE call _LdrpInsertDataTableEntry@4 ; LdrpInsertDataTableEntry(x)
...
; create and insert LDR_MODULE for ntdll
.text:7DEB64E9 call _LdrpAllocateDataTableEntry@4 ; LdrpAllocateDataTableEntry(x)
.text:7DEB64EE mov esi, eax
...
.text:7DEB6597 mov eax, dword ptr ds:_NtDllName
.text:7DEB659C mov [esi+2Ch], eax ; LDR_DATA_TABLE_ENTRY.BaseDllName
.text:7DEB659F mov eax, ds:off_7DEB6700
.text:7DEB65A4 push esi
.text:7DEB65A5 mov [esi+30h], eax ; LDR_DATA_TABLE_ENTRY.BaseDllName.Buffer
.text:7DEB65A8 call _LdrpInsertDataTableEntry@4 ; LdrpInsertDataTableEntry(x)
...
.text:7DEB65B5 mov _LdrpNtDllDataTableEntry, esi
...
; load kernel32.dll module
.text:7DEB6665 push eax
.text:7DEB6666 mov esi, offset word_7DEB670C
.text:7DEB666B push esi
.text:7DEB666C push 0
.text:7DEB666E push 0
.text:7DEB6670 call _LdrLoadDll@16 ; LdrLoadDll(x,x,x,x)
...
; load kernelbase.dll module
.text:7DEF137C push eax
.text:7DEF137D push offset word_7DEF14C0
.text:7DEF1382 push 0
.text:7DEF1384 push 0
.text:7DEF1386 call _LdrLoadDll@16 ; LdrLoadDll(x,x,x,x)
...
To by potwierdzało otrzymane wyżej zawartości list podejrzane debuggerem. O ile kolejność ładowania i mapowania do pamięci jest stała i odzwierciedla rzeczywistość, to kolejność inicjalizacji jest inna. A to dlatego, że kernel32 zależy od kernelbase, więc jego inicjalizacja będzie “odpalana” wtedy, gdy inne zależności będą już “gotowe”.
W ntdll z Windows 8 i 10 można znaleźć podobny kod. Nie spodziewałbym się aby to się szybko zmieniło, ale wykonałem testy i wszyło to samo co pod 7-mką. Teoretycznie można więc nadal bazować na kolejności danych w listach.
; post-XP/Win7+
LoadOrder: proc, ntdll, kernel32, kernelbase, ...
MemoryOrder: proc, ntdll, kernel32, kernelbase, ...
InitOrder: ntdll, kernelbase, kernel32, ...
W większości implementacji na jakie trafiałem, metoda opierająca się na kolejności, bazowała na kolejności inicjalizacji modułów (lista InInitializationOrderModuleList). Tej właśnie, która jest zależna poniekąd od implementacji, i której zawartość na dowolnym systemie ciężko jednoznacznie przewidzieć (vide hooki antiwirusowe i inne moduły inicjalizowane przy starcie procesu lub manipulujące tą listą).
Dlatego jeśli już chce się korzystać z tej metody, to ma to jakiś sens tylko na pozostałych listach, wtedy kernel32 będzie 3 modułem. Taki kod można zapisać w kilku prostych linijkach:
bits 32
mov eax, [fs:0x30] ; PEB
mov eax, [eax + 0x0C] ; PEB->Ldr
mov eax, [eax + 0x0C] ; 1st module - Ldr.InLoadOrderModuleList.Flink
mov eax, [eax] ; 2nd module - Module.InLoadOrderLinks.Flink
mov eax, [eax] ; 3rd module - Module.InLoadOrderLinks.Flink
mov eax, [eax + 0x18] ; kernel32 base address - Module.DllBase
Do testów i zabawy, lepiej użyć jakieś prostej aplikacji, aby potwierdzić poprawne działanie. Ja sobie napisałem coś takiego:
__declspec(naked)
HMODULE FindKernel32Handle() {
__asm {
mov eax, fs:[0x30] // PEB
mov eax, [eax + 0x0C] // PEB->Ldr
mov eax, [eax + 0x0C] // 1st entry (InLoadOrderModuleList)
mov eax, [eax] // 2nd entry
mov eax, [eax] // 3rd entry
mov eax, [eax + 0x18] // kernel32 base address
ret
};
}
int main() {
HMODULE mod1 = GetModuleHandleA("kernel32.dll");
HMODULE mod2 = FindKernel32Handle();
printf("%p %p %d", mod1, mod2, mod1 == mod2);
return 0;
}
Niestety __asm nie jest dostępny dla x64 projektów VS, więc eksperymentuję na x86. Ale kod dla x64 jest podobny. Jedyną różnicą są offsety do danych pól w strukturach, wynikające z różnych rozmiarów wskaźników.
bits 64
mov rax, [gs:0x60] ; PEB
mov rax, [rax + 0x18] ; PEB->Ldr
mov rax, [rax + 0x10] ; 1st module - Ldr.InLoadOrderModuleList.Flink
mov rax, [rax] ; 2nd module - Module.InLoadOrderLinks.Flink
mov rax, [rax] ; 3rd module - Module.InLoadOrderLinks.Flink
mov rax, [rax + 0x30] ; kernel32 base address - Module.DllBase
Po asemblacji w nasm-ie sformatowany kod binarny gotowy do użycia:
//
// find_kernel32_x86
//
// \x64\xA1\x30\x00\x00\x00\x8B\x40\x0C\x8B
// \x40\x0C\x8B\x00\x8B\x00\x8B\x40\x18\
//
const unsigned char fk32x86[] = {
0x64, 0xA1, 0x30, 0x00, 0x00, 0x00, 0x8B, 0x40, 0x0C, 0x8B,
0x40, 0x0C, 0x8B, 0x00, 0x8B, 0x00, 0x8B, 0x40, 0x18
};
//
// find_kernel32_x64
//
// \x65\x48\x8B\x04\x25\x60\x00\x00\x00\x48
// \x8B\x40\x18\x48\x8B\x40\x10\x48\x8B\x00
// \x48\x8B\x00\x48\x8B\x40\x30
//
const unsigned char fk32x64[] = {
0x65, 0x48, 0x8B, 0x04, 0x25, 0x60, 0x00, 0x00, 0x00, 0x48,
0x8B, 0x40, 0x18, 0x48, 0x8B, 0x40, 0x10, 0x48, 0x8B, 0x00,
0x48, 0x8B, 0x00, 0x48, 0x8B, 0x40, 0x30
};
Kod ten bez problemu powinien działać od Windowsa w wersji XP do najnowszych 10-tek. Poniżej XP, na przykład na 2000 albo jakimś starym NT mogą być małe problemy. Tam bodajże kernel32 nie jest pod stałym indeksem. Nie mniej nie mam obecnie możliwości sprawdzenia tego. Ale czy ktoś potrzebuje aż taką kompatybilność?
W miedzy czasie odkryłem też jeszcze inny, dodatkowy problem. Trzeba jednak wziąć pod uwagę pewien fakt, że w przypadku aplikacji .NET-owych, pomimo tego, że proces jest inicjalizowany podobnie jak zwykły x86/x64, to kolejność ładowanych modułów jest zabużona. W czasie mapowania modułu głównego (prawdopodobnie) system ładuje bootstrapową .NET-ową bibliotekę mscoree.dll, będącą rzeczywistym entry-pointem aplikacji w świat dot-net-u.
ModLoad: 00a00000 00a08000 SimpleNetApp.exe
ModLoad: 77d50000 77eb9000 ntdll.dll
ModLoad: 68200000 68256000 C:\Windows\SYSTEM32\MSCOREE.DLL
ModLoad: 77820000 77920000 C:\Windows\system32\KERNEL32.dll
ModLoad: 75630000 75709000 C:\Windows\system32\KERNELBASE.dll
A, że moduł ten jest ładowany w czasie mapowania, które występuje przed załadowaniem modułu kernel32 i kernelbase kolejność w listach ulega drobnej zmianie.
; .net process
LoadOrder: proc, ntdll, mscoree, kernel32, kernelbase, ...
MemoryOrder: proc, ntdll, mscoree, kernel32, kernelbase, ...
InitOrder: ntdll, kernelbase, kernel32, mscoree, ...
Teraz mój prosty, krótki i piękny kod nie zadziała, bo 3-cim modułem nie jest spodziewany kernel32, ale dot-net-owe jądro mscoree. Trzeba znaleźć inne, bardziej uniwersalne rozwiązanie, z ewentualną iteracją całej listy, czego bardzo chciałem uniknąć.
Niektórzy sobie z takimi problemami (różna kolejność modułów na różnych systemach i procesach) radzili poprzez iterowanie po liście, aż do napotkania modułu o nazwie długiej na 12 znaków. Co niekoniecznie zawsze musi zwrócić poprawny wynik. Mogą przecież pojawić się tuż przed poszukiwanym modułem inne z nazwą o podobnej długości i już będzie zonk.
Ja, jeśli musiałbym iść tą drogą, to wolałbym jednak porównać także pełną nazwę tych 12 znakowych modułów, aby mieć pewność, że znalazłem dokładnie to czego szukałem. Taki kod nie byłby skomplikowany, ale nieco dłuższy:
; push "kernel32.dll" onto stack
push 0x4c4c442e ; .DLL
push 0x32334c45 ; EL32
push 0x4e52454b ; KERN
mov eax, fs:[0x30] ; PEB
mov ebx, [eax + 0x0C] ; PEB->Ldr
add ebx, 0x0C ; ptr to Ldr.InLoadOrderModuleList.Flink
next:
mov ebx, [ebx] ; Module.InLoadOrderModuleList.Flink
movzx ecx, word ptr [ebx + 0x2C] ; Module.BaseDllName.Length
cmp ecx, 12 * 2 ; Length == 12 unicode
jne next ; jmp to next if not
mov edi, [ebx + 0x30] ; Module.BaseDllName.Buffer
mov esi, esp ; kernel32.dll string on stack
shr ecx, 1 ; length in chars (ecx/2)
name:
lodsb ; load char of kernel32 string
mov ah, [edi] ; load char of module name
cmp ah, 'a' ; char is upper?
jl noup ; if yes go to cmp
sub ah, 0x20 ; convert to uppercase
noup:
cmp ah, al ; if char mismatch
jne next ; jmp to next module
add edi, 2 ; next unicode char
loop name ; unitl all chars checked
mov eax, [ebx + 0x18] ; Module.DllBase
add esp, 12 ; clean stack
Pominąłem w nim sprawdzanie, czy przypadkiem nie przeleciałem już po całej liście i nie zaczęła się ponowna iteracja. Nie jest to potrzebne w tym przypadku, bo zakładam (co w rzeczywistości musi być prawdą), że poszukiwany kernel32 gdzieś w tej liście się znajduje.
Dodanie takowego sprawdzania wraz z przekazywaniem pointera na ciąg znaków z nazwą szukanego modułu pozwoli stworzyć odpowiednik funkcji GetModuleHandle. Funkcja może się przydać przy szukaniu dowolnego modułu zmapowanego do przestrzeni adresowej danego procesu.
HMODULE FindModuleHandle(const WCHAR* Name, SIZE_T Length) {
PEB_LDR_DATA* Ldr = NtCurrentTeb()->ProcessEnvironmentBlock->Ldr;
LIST_ENTRY* Head = &Ldr->InMemoryOrderModuleList;
LIST_ENTRY* Entry = Head->Flink;
while (Entry != Head) {
LDR_DATA_TABLE_ENTRY* Module = CONTAINING_RECORD(Entry, LDR_DATA_TABLE_ENTRY, InMemoryOrderLinks);
if (Module->BaseDllName.Length == Length && wcsicmp(Module->BaseDllName.Buffer, Name) == 0)
return reinterpret_cast<HMODULE>(Module->DllBase);
Entry = Entry->Flink;
}
return nullptr;
}
Pod różnymi wersjami systemu i w różnych procesach, nazwy i ścieżki do plików modułów są zapisane różną wielkością liter, czasem małymi, a czasem dużymi. Dlatego ewentualne porównania należy uodpornić na wielkość liter w nazwach, co uczyniłem w powyższych kodach.
Niestety case-insensitive uniemożliwia mi porównywanie stringów z nazwami w blokach po 4 bajty na raz, co przy długościach będących wielokrotnością słowa/dwusłowa danej architektury jest często wykorzystywane. Większość dobrych bibliotek standardowych lub kompilatorów potrafi nieźle zoptymalizować typowe operacje na blokach pamięci, jak na przykład kopiowanie czy porównywanie, często jednym zamachem operując na 4 lub 8 bajtach danych, a nawet na 16/32/64 bajtach przy wykorzystaniu SSE/AVX.
W wielu softach, szczególnie tych złośliwych, często unika się zapisywania wprost w kodzie i pamięci, czy na stosie, nazw importowanych w run-time funkcji i modułów. Zamiast tego stosuje się proste funkcje haszujące i porównuje wynik z zapisanym skrótem. Poniekąd, aby uniemożliwić lub jakoś utrudnić wykrycie, analizę przez rożnego rodzaju oprogramowanie zabezpieczające, a z drugiej strony by przyspieszyć poszukiwanie funkcji, gdy trzeba wielokrotnie przeszukiwać zbiór dostępnych (eksportowanych) funkcji (chociaż chyba niekoniecznie, jeśli gdzieś nie zapiszemy sobie listy wyliczonych hash-y).
Natrafiłem kilka razy w takich kodach na bardzo prostą funkcję haszującą ROR-13, co by świadczyło, że jest często wykorzystywana w różnych shellcodach i malware. Sumuje ona poszczególne znaki stringa i przesuwa cyklicznie w każdym kroku sumę o 13 bitów w prawo.
Implementacja takiej funkcji w języku C:
uint32_t ror13_hash(const char* name)
{
uint32_t hash = 0;
while (*name) {
hash = (hash >> 13) | (hash << (32 - 13));
hash += (uint32_t)*name++;
}
return hash;
}
Kod taki można zapisać w Perlu w prostym skrypcie:
#!/usr/bin/perl -w
# ROR-13 hash tool
use strict;
sub ror13 {
my $n = shift;
return ($n >> 13) | ($n << (32 - 13)) & 0xFFFF_FFFF;
}
sub hash {
my $hash = 0;
foreach my $char (unpack("C*", shift)) {
$hash = ror13($hash) + $char;
}
return $hash;
}
while(<>) {
$_ =~ s/^\s+|\s+$//g; # trim
printf("%08x\t%s\n", hash($_), $_);
}
Ułatwia on liczenie funkcji skrótu z większej ilości danych, po przekierowaniu strumienia:
C:\Users\malcom>type names.txt | perl hash.pl
6e2bca17 KERNEL32.DLL
7c0dfcaa GetProcAddress
Teraz można przepisać poprzedni asemblerowy kod pozbywając się string a zrzuconego na stos, a zamiast niego wpakować 32-bitowego hasha w kodzie. Dla modułu kernel32.dll w wersji uppercase wynosi dokładnie 6e2bca17.
mov eax, fs:[0x30] ; PEB
mov ebx, [eax + 0x0C] ; PEB->Ldr
add ebx, 0x0C ; ptr to Ldr.InLoadOrderModuleList.Flink
next:
mov ebx, [ebx] ; Module.InLoadOrderModuleList.Flink
movzx ecx, word ptr [ebx + 0x2C] ; Module.BaseDllName.Length
cmp ecx, 12 * 2 ; Length == 12 unicode
jne next ; jmp to next if not
shr ecx, 1 ; length in chars (ecx/2)
mov esi, [ebx + 0x30] ; Module.BaseDllName.Buffer
xor edi, edi ; hash = 0
name:
lodsw ; load wchar of name
cmp al, 'a' ; char is upper?
jl noup ; if yes go to cmp
sub al, 0x20 ; convert to uppercase
noup:
movzx eax, al ; eax = al
ror edi, 13 ; ror13
add edi, eax ; hash + char
loop name ; unitl all chars read
cmp edi, 0x6e2bca17 ; hash == ror13(kernel32.dll)
jne next ; jmp to next if not
mov eax, [ebx + 0x18] ; Module.DllBase
W powyższym kodzie z uwagi na fakt, że operowałem na szukaniu standardowej nazwy systemowej, wyliczałem hasha z wersji ANSI nazwy (degradując w locie 2-bajtowy znak na jego 1-bajtowy odpowiednik). W przypadku szukania różnych niestandardowych (i niesystemowych) modułów, gdzie w systemie nazwy plików mogą przybrać dowolną formę (inne języki), lepiej zrobić to poprawnie. Wystarczy zmodyfikować kod, zastępując rejestr al na ax w instrukcji movzx eax, al.
Jedno z przedstawionych tutaj rozwiązań, jakie udało mi się zakodować i przetestować, będę musiał wkrótce wprowadzić w swoim syringe, zamiast obecnej implementacji używającej hard-kodowanych adresów funkcji pobranych w procesie wstrzykującym. Co jak wspomniałem na początku, na nowych systemach może nie działać poprawnie.
Wybór takiego a nie innego rozwiązania zależy głównie od potrzeb i celu jaki chce się osiągnąć. Gdy atakujemy specyficzny proces lub grupę procesów to znając ofiarę można wykorzystać dedykowane dla niej rozwiązanie. Dla zwykłych procesów w większości systemów wystarczy przedstawione wyżej kilka linijek (bajtów) kodu na złapanie 3-ego załadowanego modułu Dla nieco bardziej uniwersalnych zastosowań trzeba wybrać nieco bardziej rozbudowany kod…
Swoją drogą metoda operująca na PEB-ie jest najpopularniejsza i niezawodna, ale istnieje jeszcze kilka innych metod i sposobów na zlokalizowanie modułu kernel32 w przestrzeni adresowej procesu. Nie miałem z nimi styczności, ale widziałem różne propozycje, więc może kiedyś, w niedalekiej przyszłości, pobawię się nimi zobaczę co z tego wyniknie.
A, gdy już mam adres bazowy modułu kernel32.dll w interesującym mnie procesie, mogę przejść dalej, do szukania adresu funkcji GetProcAddress, ale o tym w następnym odcinku… ;)
Aktualizacja 12/04/2017 @ 23:00 Trochę przeredagowałem notatkę uwzględniając zmiany jakie odkryłem w związku z procesami dot-NET-owymi, przy których trochę zmienia się kolejność ładowania systemowych modułów.
Komentarze (1)
wow, nie spodziewałem się że znajdę na ten temat artykuł w języku polskim.
Bardzo przydatne informację, dziękuję.