Shellcode: EAT i funkcja GetProcAddress
• tech • 1902 słowa • 9 minut czytania
Ta notatka jest częścią serii Shellcode: moje eksperymenty. Zapoznaj się z pozostałymi wpisami.
Gdy już w swoich rękach mam adres bazowy modułu kernel32.dll (zlokalizowany na przykład sposobem opisanym w poprzednim moim wpisie) kolejnym krokiem jest poznanie adresu dowolnej funkcji znajdującej się w tym module. W wielu sytuacjach wystarczy dorwać się tylko do GetProcAddress i LoadLibrary, co ułatwi wykorzystanie dowolnej innej funkcji z Windows API lub innej biblioteki. W celu znalezienia potrzebnej funkcji w danym module, chociażby osławionego GetProcAddress, muszę sobie napisać jego prosty odpowiednik. To jest niezły paradoks, aby dostać się do GetProcAddress trzeba mieć własny GetProcAddress. I w tej notatce skupię się właśnie na tym zagadnieniu ;)
Każdy plik wykonywalny i biblioteka dynamiczna w systemie Windows używa formatu PE (Portable Executable), który jasno specyfikuje zawartość pliku. Nie chcę tutaj opisywać całej struktury i formatu takich plików, dlatego po szczegóły odsyłam do sieci.
Najważniejsza w tej chwili jest informacja, że oprócz sekcji z danymi, kodem, zasobami, etc… w pliku znajdują się także specyficzne dane, niezbędne do poprawnego działania zawartego w nim kodu. Takimi danymi są m.in. tablica importów i eksportów, handlery wyjątków, zasoby, tablice relokacji etc. Dostęp do nich wiedzie przez tablicę DataDirectory umiejscowioną na końcu opcjonalnego nagłówka PE (OptionalHeader). Pierwszym wpisem w katalogu danych jest informacja o lokalizacji i rozmiarze katalogu eksportów (IMAGE_EXPORT_DIRECTORY), który właśnie w tej chwili mnie najbardziej interesuje.
Podglądowy rysunek, ukazujący zarys tego wszystkiego w rzeczywistości, powinien nieco ułatwić zrozumienie i rozlokowanie poszczególnych elementów wewnątrz pliku lub pamięci, gdzie ów plik został zmapowany przez loader systemowy.

[sorry… nie udało mi się jeszcze dobrze przetworzyć planowanego rysunku, dlatego narazie tylko zlepek z jakis dokumentacji Microsoftu]
Niestety windbg nie zawiera za dużo definicji odnośnie plików PE zawiera większość definicji związanych z plikami PE, ale dla potrzebnego mi tutaj katalogu polecenie dt zwraca błąd:
0:000> dt _IMAGE_EXPORT_DIRECTORY
Symbol _IMAGE_EXPORT_DIRECTORY not found.
Nie chce się bawić w pokazywanie bebechów w hex-edytorze lub na zrzutach pamięci, dlatego dalej będę się posługiwał bezpośrednio strukturami. Co i tak wydaje się lepszym posunięciem. Definicje te są stałe, nie tak jak w przypadku PEB-a i powiązanych z nich danych, które w internalsach Windowsa mogą się zmieniać z wersji na wersję.
Katalog eksportowanych funkcji opisuje struktura IMAGE_EXPORT_DIRECTORY:
struct IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name;
DWORD Base;
DWORD NumberOfFunctions;
DWORD NumberOfNames;
DWORD AddressOfFunctions;
DWORD AddressOfNames;
DWORD AddressOfNameOrdinals;
}
Nazwy poszczególnych jej elementów dobrze opisują przeznaczenie, a powiązania pomiędzy poszczególnymi tablicami idealnie odzwierciedla przedstawiony wyżej rysunek. Mimo tego jest do dobry moment, aby przypomnieć sobie jak to dokładnie wygląda w praktyce. Najważniejsze dane o eksportach znajdują się w 3-ech powiązanych ze sobą tablicach, do których adresy (RVA) znajdują się w strukturze.
Najistotniejsza jest tablica adresów funkcji EAT (Export Address Table) znajdująca się pod adresem AddressOfFunctions. Jej zawartość to adresy wszystkich eksportów modułu. Zatem ilość elementów w niej zawartych określana zmienną NumberOfFunctions odpowiada ilości eksportów.
Następne dwie tablice związane są z nazwami eksportowanych symboli. Tablica nazw ENT (Export Names Table) leżąca w pamięci pod adresem AddressOfNames przechowuje wskaźniki do stringów (ASCII) opisujących poszczególne eksporty. Liczba jej elementów określona jest w NumberOfNames. Tablica ta jest posortowana, co umożliwia loaderowi wykorzystanie binarnego przeszukiwania jej zawartości, przyspieszając znalezienie danego elementu. Ale, wtedy żeby znaleźć adres odpowiadający danej nazwie potrzebna jest tablica porządkowa nazw EOT (Export Ordinal Table). Mieści się ona pod AddressOfNameOrdinals, a jej zawartość mapuje nazwę - indeks ENT na odpowiedni indeks EAT. W wyniku tego otrzymuje się adres funkcji.
Warto pamiętać, że Base jest startowym numerem porządkowym dla tablicy EAT. Wraz z indeksem tworzą rzeczywisty numer (ordinal) funkcji. Jest to istotne przy importowaniu po numerze, bo oczywiście nie wszystkie elementy muszą być eksportowane po nazwie.
Teraz mogę sobie napisać w języku C++ odpowiednik funkcji GetProcAddress. Implementacja taka jest bardzo prosta, a że nie używa żadnych dodatkowych funkcji, prócz strcmp, idealnie może nadać się na kod do wstrzykiwania.
template<typename T>
inline T GetPtr(HMODULE base, ULONG rva) {
return reinterpret_cast<T>(reinterpret_cast<ULONG_PTR>(base) + rva);
}
PROC FindProcAddress(HMODULE ModuleBase, const char* ProcName) {
auto ntHdr = GetPtr<const IMAGE_NT_HEADERS*>(
ModuleBase, reinterpret_cast<const IMAGE_DOS_HEADER*>(ModuleBase)->e_lfanew
);
auto& dataDir = ntHdr->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT];
// no export data
if (!dataDir.VirtualAddress || !dataDir.Size)
return nullptr;
auto expDir = GetPtr<const IMAGE_EXPORT_DIRECTORY*>(ModuleBase, dataDir.VirtualAddress);
auto funcs = GetPtr<const PDWORD>(ModuleBase, expDir->AddressOfFunctions);
auto names = GetPtr<const PDWORD>(ModuleBase, expDir->AddressOfNames);
auto nords = GetPtr<const PSHORT>(ModuleBase, expDir->AddressOfNameOrdinals);
if (HIWORD(ProcName) == 0) {
// import by ordinal
WORD ord = LOWORD(ProcName);
DWORD ordBegin = expDir->Base;
DWORD ordEnd = expDir->Base + expDir->NumberOfFunctions;
if (ord < ordBegin || ord > ordEnd)
return nullptr;
return GetPtr<PROC>(ModuleBase, funcs[ord - ordBegin]);
} else {
// import by name
for (ULONG i = 0; i < expDir->NumberOfNames; i++) {
char* name = GetPtr<char*>(ModuleBase, names[i]);
int ord = nords[i];
if (strcmp(name, ProcName) == 0)
return GetPtr<PROC>(ModuleBase, funcs[ord]);
}
}
return nullptr;
}
Nie jest to idealne i pełne odzwierciedlenie systemowej funkcji do pobierania adresów, bo nie obsługuje pewnej dodatkowej funkcjonalności zwanej Export Forwarding. Mechanizm ten pozwala przekierować eksport z jednego modułu na dowolną funkcję (eksportowaną) w innym module. A całym resolwowaniem zajmuje się systemowy loader dll-ek. Temat przekierowań przy eksportach zostawiam na inną okazję.
Teraz, gdy już wszystko jest wiadome, łatwo skrobnąć te kilkanaście linijek kodu w asemblerze, który bezproblemowo poradzi sobie ze znalezieniem potrzebnej funkcji. Taki kod, buszujący po tablicy eksportu, szukający adresu funkcji po jej nazwie udało mi się zapisać w takiej postaci:
; FindProcAddress
; esp+4 module base
; esp+8 proc name
; eax return proc or 0
mov esi, [esp + 4] ; base address
mov eax, [esi + 0x3C] ; offset to PE header
mov ebx, [esi + eax + 0x78] ; IMAGE_EXPORT_DIRECTORY RVA
xor eax, eax
test ebx, ebx ; if no exports
jz end ; jmp to end and return 0
add ebx, esi ; VA to export dir
mov ecx, [ebx + 0x18] ; NumberOfNames
mov edx, [ebx + 0x20] ; AddressOfNames RVA
add edx, esi ; VA to ENT
next:
xor eax, eax ; if all processed ecx == 0
jecxz end ; jmp to end and return 0
dec ecx ; dec names counter
mov esi, [edx + ecx * 4] ; RVA to function name
add esi, [esp + 4] ; VA of current name
mov edi, [esp + 8] ; serach function name
compare:
lodsb ; load char of function name
mov ah, [edi] ; load char of searched name
cmp al, ah ; if char mismatch
jne next ; jmp to next name
test ah, ah ; if all chars cmp ('\0')
jz found ; jmp to found
add edi, 1 ; next char
jmp compare ; until all chars cmp
found:
mov esi, [esp + 4] ; base address
mov eax, [ebx + 0x24] ; AddressOfNameOrdinals RVA
add eax, esi ; VA to EOT
mov edx, [ebx + 0x1C] ; AddressOfFunctions RVA
add edx, esi ; VA to EAT
movzx ebx, word ptr [eax + ecx * 2] ; Ordinals[id]
mov eax, [edx + ebx * 4] ; functions[ord]
add eax, esi ; VA to function
end:
nop
Dane do wyszukania pobierane są ze stosu, a zwracany wynik, będący adresem funkcji lub 0 (w przypadku nieznalezienia szukanej funkcji) zwracany jest typowo w rejestrze eax.
Algorytm jest dokładnym odzwierciedleniem fragmentu obsługującego eksporty po nazwie z funkcji FindProcAddress. Z tym małym wyjątkiem, że całość “kręci” się od tyłu po tablicy ENT. A to dlatego, bo tak łatwiej i szybciej. W końcu dostajemy liczbę elementów i operowanie na niej bezpośrednio upraszcza kod. Inaczej trzeba byłoby w jakimś dodatkowym rejestrze (o które już ciężko) trzymać licznik, porównywać jego zawartość i sterować pętlą.
Na potrzeby testów i eksperymentów, kod ten wrzuciłem do prostej funkcji jako inline-assembler w VS. Porównując działanie z oryginalnym systemowym odpowiednikiem.
__declspec(naked)
PROC FindProcAddress(HMODULE module, const char* name) {
__asm {
...
ret
};
}
int main() {
const char* module = "kernel32.dll";
const char* func = "GetProcAddress";
HMODULE mod = GetModuleHandleA(module);
PROC f1 = GetProcAddress(mod, func);
PROC f2 = FindProcAddress(mod, func);
printf("%p %p %d\n", f1, f2, f1 == f2);
return 0;
}
Kod działa bez zarzutu ;)
W większości przypadków jednak większość twórców paskudnych rzeczy (np. malware), podobnie jak przy szukaniu modułu, pozbywa się jawnych nazw, wykorzystując haszowanie. Tutaj również można bez problemu zaaplikować znany już algorytm ROR13.
Dodanie haszowania do tej funkcji nie jest żadnym wielkim problemem. Mnie jednak interesuje tylko znalezienie dwóch funkcji: GetProcAddress i LoadLibrary. Głównie na potrzeby prostego shellcode-a lub loadera w syringe, dlatego nie musze bawić się w haszowanie.
Za to mogę w końcu porównywać od razu większe bloki nazw, do długości rejestrów, czyli po 4 bajty. Nazwy te są ułożone w danych eksportów, w tym samym fragmencie pamięci, w praktyce jeden obok drugiego z odpowiednim wyrównaniem do granicy słowa.
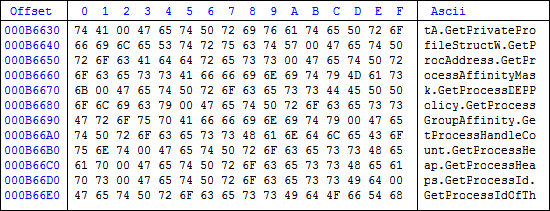
Dlatego nie bolą mnie jakiekolwiek potencjalne problemy, na jakie mógłbym trafić przy niepoprawnym dostępie do obszaru pamięci spoza wydzielonego fragmentu. Mogę także pominąć jakiekolwiek walidacje, bo wiem co szukam i wiem, że to znajdę. W końcu kernel32 na pewno ma tablicę eksportów i szukane funkcje się w niej znajdują.
; FindProcs
; esi - kernel32 base address
; return:
; eax - GetProcAddress
; ebx - LoadLibraryA
mov eax, [esi + 0x3C] ; offset to PE header
mov ebx, [esi + eax + 0x78] ; IMAGE_EXPORT_DIRECTORY RVA
add ebx, esi ; VA to export dir
mov edx, [ebx + 0x20] ; AddressOfNames RVA
add edx, esi ; VA to ENT
xor ecx, ecx ; name idx = 0
next:
mov eax, [edx] ; RVA to current name
add eax, esi ; VA to curent name
add edx, 4 ; edx to next name
inc ecx ; inc name idx
cmp dword ptr [eax + 0], 0x50746547 ; GetP
jnz next
cmp dword ptr [eax + 4], 0x41636f72 ; rocA
jnz next
cmp dword ptr [eax + 8], 0x65726464 ; ddre
jnz next
; this can be omitted, kernel32 doesn't have
; any other function with GetProcAddre prefix
cmp word ptr [eax + 12], 0x7373 ; ss
jnz next
dec ecx ; real name idx
mov eax, [ebx + 0x24] ; AddressOfNameOrdinals RVA
add eax, esi ; VA to EOT
movzx ecx, word ptr [eax + ecx * 2] ; func idx
mov ebx, [ebx + 0x1c] ; AddressOfFunctions RVA
add ebx, esi ; VA to EAT
mov edx, [ebx + ecx * 4] ; function RVA
add edx, esi ; VA to function
push edx ; push GetProcAddress
; get LoadLibrary address by call to GetProcAddress
push 0 ; \0
push 0x41797261 ; aryA
push 0x7262694C ; Libr
push 0x64616F4C ; Load
push esp ; "LoadLibraryA"
push esi ; kernel32 base address
call edx ; GetProcAddress
add esp, 16 ; clean stack
pop ebx ; GetProcAddress
xchg ebx, eax ; LoadLibraryA
W powyższym kodzie, zamiast szukać ręcznie także funckji LoadLibraryA, dla przykładu, pobrałem jej adres poprzez call do zresolwowanej wcześniej funkcji GetProcAddress. To wszystko znacznie upraszcza i skraca kod. A przede wszystkim przy takich kodach przecież o to także chodzi, rozmiar ma jakieś tam znaczenie ;)
To czy tak naprawdę potrzeba w kodzie dostępu do oryginalnego GetProcAddress zależy głównie od tego co chce się osiągnąć i ile potrzeba zewnętrznych funkcji. Bo jeśli już napiszę sobie implementację do resolwowania adresów funkcji, to mogę ją przecież wykorzystywać do wszelkich dalszych poszukiwań. Z drugiej strony, gdy wstrzykuję pełny moduł do procesu to wystarczy mi tylko LoadLibrary, a dalej już załadowana biblioteka, często napisana w języku wyższego poziomu (na przykład C++) sama sobie poradzi z całym niezbędnym do jej działania środowiskiem.
Teraz mając dostęp do różnych systemowych funkcji, wreszcie mogę napisać jakiś prosty shellcode. Taki mały fragment kodu binarnego mogę wstrzyknąć do procesu i uruchomić w jego kontekście. Ale to już w następnej odsłonie ;)
Komentarze (0)