SaeLog #3: Fake EEPROM
• tech • 1401 słów • 7 minut czytania
Ta notatka jest częścią serii Saleae Logic Hack. Zapoznaj się z pozostałymi wpisami.
Już od jakiegoś czasu przyglądałem się kodowi zaszytemu w chipie oraz starałem przypomnieć sobie asemblera 8051. Robiąc sobie małą przerwę od analizy firmware, całkiem przypadkiem trafiłem na małą niespodziankę. Po odłączeniu pamięci EEPROM (wyjęcie zworki) już po wykryciu i załadowaniu oprogramowania do układu, nie stwarza żadnych widocznych problemów z softem. Aplikacja się nie wywala i wydaje się działać poprawnie. Mimo, iż CY7C68013A będzie odpowiadał na odczyty z I2C spod adresu 0xA0 jakimiś losowymi danymi-śmieciami.
Wcześniej takiego scenariusza nie brałem pod uwagę, trzymając się tego co zaczytałem gdzieś w sieci, że to nie pomaga, więc nawet nie próbowałem tego robić. To dało mi do myślenia, żeby jednak powinienem spróbować obejść problem w aplikacji fake-ując odczyty z pamięci. Nim rozkręcę się w crackowaniu i modyfikowaniu firmware.
ReadEeprom
W SaeLog #2 prezentowałem dokładniejsze działanie funkcji LogicAnalyzerDevice::ReadEeprom i komunikacji z pamięcią EEPROM. W istocie najprościej byłoby nadpisać tą funkcję czymś w rodzaju:
void LogicAnalyzerDevice::ReadEeprom(void* obj, int address, char* buffer, int length) {
std::memset(buffer, 0, length);
}
Zwracanie pustych danych jest dobrym pomysłem. Nie powinno to psuć, ani wpływać na działanie, w przeciwieństwie do losowych danych.
Przyglądając się bliżej kodowi, zauważyłem, że IDA olała mały fragment kodu, który de-facto jest dodatkowym wejściem do funkcji. Istnieje pewne dziwne odwołanie wraz z kodem, które omija cześć ciała funkcji i przekazuje działanie przed blokiem kodu, który próbuje zczytać dane z portu. Oznaczono to na czerwono na poniższym obrazku. Scieżka ta zaczyna się od kodu ulokowanego pod 5120EA.
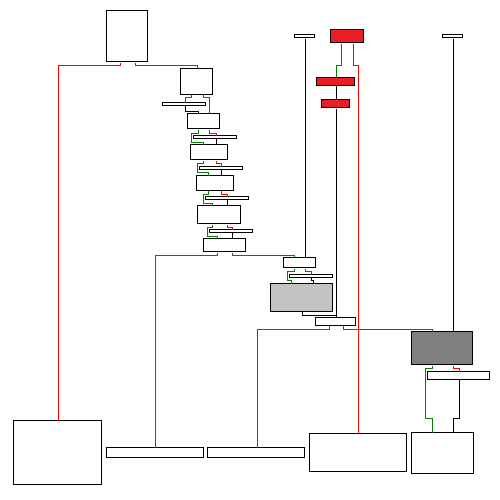
Może jest to jakiś błąd, a może w pewnych sytuacjach sterowanie przechodzi właśnie tą ścieżką. Dlatego dla pewności zdecydowałem się zmodyfikować tylko wymagane fragmenty, czyli blok kodu z wywołaniem do Read i Write na WindowsUsbDevice (szary i ciemnoszary kolor), a resztę pozostawić nietknietą. Fragment z zapisem to tak na wszelki wypadek, aby pozbyć się ewentualnego wpływu wysłanych lub nieodebranych danych, które mogłyby się zakolejkować i przy innych operacjach wpływać na wyniki lub inną funkcjonalność.
Zapis możemy pominąć jakimś skokiem, co wydaje się jedynym sensownym rozwiązaniem. Zawsze możemy zastąpić istniejący kod pustymi instrukcjami nop lub innymi, choć nie będzie to optymalne działanie. Sama modyfikacja wywołania call edx nie jest poprawna, bo wypadłoby jeszcze ogarnąć stos, gdyż standardowo metody lecą jako thiscall i to wywoływany sprząta po sobie. Dlatego można to ogarnąć dorzucając add esp, 0Ch (83 C4 0C) zamiast wołanego call-a na edx (FF D2), ale niestety zabraknie wtedy miejsca na 1 bajt kodu. Można pożreć poprzedzającą instrukcję mov zyskując dodatkowe 2 bajty.
Zdecydowałem się jednak na skok. Musimy pominąć cały blok kodu, czyli 21 bajtów, skacząc do 0x00512072. Co dla relatywnego skoku wyjdzie 19 bajtów w przód: 0x512072 - 0x51205D - 2. Modyfikacja prosta, podmieniamy kod pod adresem 0x51205D na kolejno 75 13, co odpowiada wstawianej instrukcji jmp +13h. I procesor nie będzie marnował czasu na zbędne instrukcje.
Blok kodu, gdzie następuje wywołanie czytania z portu USB, należy zastąpić wywołaniem do funkcji memset. Tak się składa, że aplikacja korzysta z tej funkcji i linkuje CRT statycznie, więc jest ona dostępna pod adresem 9D4960. W typowym call-u z relatywnym adresem (E8) używany jest offset wględem następnej instrukcji, podobnie jak w skokach relatywnych, co wymaga jego wyliczenia. Tak będzie i tutaj, offset ten wynosi 0x4C28B9 (0x9D4960 - 0x5120A2 - 5), a cały kod modyfikujący:
00512097 movzx edx, byte ptr [ebp+length] ; 0F B6 55 14
0051209B push edx ; 52
0051209C push 0 ; 6A 00
0051209E mov edx, [ebp+buffer] ; 8B 55 10
005120A1 push edx ; 52
005120A2 call _memset ; E8 B9 28 4C 00
005120A7 add esp, 0Ch ; 83 C4 0C
005120AA jmp short loc_5120B1 ; EB 05
Warto pamiętać, że memset tak, jak cały C run-time, korzysta domyślnej konwencji wywołania w C i C++, czyli cdecl, gdzie wywołujący musi posprzątać. Dlatego po wywołaniu funkcji należy zadbać o porządki na stosie, modyfikując wartość rejestru esp.
Tak zmodyfikowana funkcja będzie zwracać puste dane w buforze, bez ingerencji i komunikacji z urządzeniem.
WriteEeprom
Dla pełności możemy też zmienić funkcję wysyłającą dane do zapisu w pamięci EEPROM. Skoro fejkujemy odczyt, a dostęp do pamięci z obecnego kodu firmware i tak nie jest osiągalny, to nie ma potrzeby, aby wypuszczać z komputera takowe żądania.
Tutaj to można pojechać po bandzie i olać całą zawartość funkcji. Funkcja nic nie zwraca, a przyjmuje tylko 2 argumenty, więc mój krok to zmiana 3 pierwszych bajtów kodu funkcji na odpowiedniki następującej instrukcji:
00511C50 retn 8 ; C2 08 00
No i funkcja stała się widmem ;)
GetIdFromDevice
To co osiągnęliśmy z fejkowaniem funkcji dostępowych do pamięci EEPROM niestety nie do końca sprawdza się w działaniu. Oczywiście nie są to problemy ze zmodyfikowanym kodem, a bardziej z logiką samej aplikacji. Gdy uruchomimy tak zmodyfikowany kod programu, to aplikacja i tak się posypie. W logach znajdziemy informacje o zaistniałym problemie:
File: ..\source\LogicAnalyzerDevice.cpp
Function: LogicAnalyzerDevice::GetIdFromDevice, Line: 257
Error: GetIdFromDevice failed;
Gdy zamienię wypełnianie pamięci wartościami 0 na inną wartość - na przykład 1, w zmodyfikowanej ReadEeprom, to GetIdFromDevice przejdzie bez problemu. W sumie przy losowych danych, bez zworki, też wszystko działało. Niestety muszą być zera, aby nie wpływać na działanie innych funkcjonalności, dlatego trzeba także “naprawić” działanie tejże funkcji.
Po szybkim zerknięciu na kod widać 2 wywołania funkcji odczytującej pamięć, obie z tymi samymi argumentami, co odzwierciedla odczyt 8 bajtów zaczynając od adresu 8. Pomiędzy tymi odczytami występują różne operacje i inne funkcje wyliczające bliżej nie sprecyzowaną wartość nieznanym bliżej algorytmem. Jak to działa to idealny temat na inny odcinek. A tutaj chcę jedynie pominąć cały ten bajzel.
Pytanie czy da się to jakoś sensownie i prosto przeskoczyć? Do tego trzeba sprawdzić jak zwracany jest wynik i czy ma on jakieś znaczenie. Zapewne będzie to standardowo rejestr eax.
Tuż przed wyjściem z funkcji GetIdFromDevice widać przypisanie 4 pierwszych bajtów buforu, do którego ładowano dane, a następnie przeprowadzano operacje i wyliczenia:
005117E8 mov eax, dword ptr [esp+3Ch+buffer]
W miejscu wywołania tej funkcji, np. w konstruktorze Logic16Device zauważyć można zachowanie zwracanej wartości w jakiejś składowej obiektu:
00508018 push 1
0050801A mov ecx, esi
0050801C mov byte ptr [esp+60h+var_4], 5
00508021 call LogicAnalyzerDevice__GetIdFromDevice
00508026 mov [esi+10h], eax
Być może ten identyfikator urządzenia jest gdzieś do czegoś wykorzystywany.
Po rzucie oka na flow chart i kod asemblera, przez chwilę myślałem o wykorzystaniu jakiś skoków i pominięciu części kodu, przenosząc wykonanie kodu bezpośrednio po dodaniu do logów informacji o użyciu funkcji, wprost pod adres 5117E8, czyli ostatniego bloku. A w nim podmieniając operację mov eax, dword ptr [esp+3Ch+buffer] (4 bajty) na coś adekwatnego do typowego mov eax, 1 (5 bajtów), jak mov al, 1 i nop-y? Albo może jeszcze inaczej:
005117E8 xor eax, eax ; 31 C0
005117EA inc eax ; 40
005117EB nop ; 90
Co idealne dopasowałoby się do 4 bajtów orginalnej instrukcji.
Na szczęście w porę oprzytomniłem i mnie oświeciło, więc zrobiłem podobnie jak przy WriteEeprom. Po co bawić się skokami i całą resztą skoro nie zależy mi na tej funkcji i jej kodzie. Od razu na początku funkcji powinienem nadpisać istniejący kod czymś podobnym do tego:
005115D0 mov eax, 1 ; B8 01 00 00 00
005115D5 retn 4 ; C2 04 00
Prościej i szybciej! Proste rozwiązania są zawsze najlepsze.
Patch
Po wykonaniu wszystkich opisanych modyfikacji aplikacja rusza bez problemu. Nie ma już żadnych problemom z kompatybilnością pamięci, bo kod programu w ogóle jej nie używa.
Dla ułatwienia wszelkie zmiany można przedstawić w postaci binarnego diffa generowanego przez IDA. Jego główna zawartość prezentuje wprowadzane zmiany w pliku, pod jakim przesunięciem względem początku pliku znajduje się dana wartość i na jaką należy zamienić. I tak każdy bajt.
This difference file has been created by IDA
Logic.exe
001109D0: 55 B8
001109D1: 8B 01
001109D2: EC 00
001109D3: 83 00
001109D4: E4 00
001109D5: F8 C2
001109D6: 6A 04
001109D7: FF 00
00111050: 6A C2
00111051: FF 08
00111052: 68 00
0011145D: 8B 75
0011145E: 45 13
0011149B: 8B 52
0011149C: 4E 6A
0011149D: 04 00
0011149F: 01 55
001114A0: 8B 10
001114A1: 40 52
001114A2: 0C E8
001114A3: 52 B9
001114A4: 8B 28
001114A5: 55 4C
001114A6: 10 00
001114A7: 52 83
001114A8: 81 C4
001114A9: C6 0C
001114AA: C4 EB
001114AB: 00 05
Informacje te można wykorzystać crackując~~ patch-ując plik wykonywalny ręcznie w jakimś hex edytorze. Lub mniej mecząco za pomocą pomocnych programów jakie można znaleźć w sieci - ida_patcher lub pythonowy idadif.
Udało się prosto i szybko ogarnąć ten problem. A tak jak mówiłem na początku, nie spodziewałem się takowego scenariusza. Zanurzając się w otchłań zdiasemblowanego kodu ładowanego do chipa. O modyfikacji firmware zapewne będzie w którymś z następnych odcinków.
Komentarze (0)