Sekcje i segmenty w plikach wykonywalnych (PE)
• tech • 692 słowa • 4 minuty czytania
Mała przerwa od serii zabaw kodem analizatora logicznego. W ostatnim wpisie o ekstrakcji kodu firmware (SaeLog #4) wspomniałem o kilku innych, ciekawych tematach. Jednym z nich była kwestia związana z przechowywaniem stałych danych w sekcji .rdata, o których teraz chciałbym nieco więcej powiedzieć. A szczególnie o tym jak pisanie kodu rzutuje na generowany przez kompilator/linker plik wynikowy.
Sekcje i segmenty w PE i innych
Pliki binarne zawierające kod wykonywalny (executables), czyli zwykle exe, biblioteki DLL, czy pliki obiektowe (a także kilka innych) w większości systemów są zbliżone do siebie formatem lub budową. Ich budowa bazuje na sekcjach, bądź strumieniach. W tej chwili najbardziej interesuje mnie akurat wersja windowsowa, a w tym świecie używany jest format PE (Portable Executable). Nie będę się zajmował samym formatem, jest on nieźle opisany, w Internecie można znaleźć wiele materiałów, a najprościej zacząć od specyfikacji ze stron Microsoftu: Microsoft PE and COFF Specification.
Ograniczam się tylko do zaprezentowania poniższego obrazka, znalezionego w sieci (bodajże strony MS), który ukazuje strukturę pliku i jego mapowanie w pamięci.
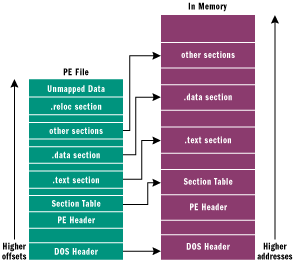
Wyraźnie widać, że sercem pliku są sekcje, w których zawarte są wszelkie informacje, czyli kod wykonywalny z niezbędnymi danymi oraz metadanymi opisującymi plik i środowisko niezbędne systemowi operacyjnemu do poprawnego zarządzania kodem wykonywalnym i jego poprawnego działania (np. importy, zasoby, thread-local-storage).
Najpopularniejsze sekcje jakie można spotkać w większości plików PE:
.text Code
.data Initialized data
.rdata Const (read-only) data
.rsrc Resources data
.reloc Relocations data
Oczywiście to tylko mała cząstka, bo istnieje ich o wiele więcej, choć nie zawsze da się je zauważyć. Na przykład istnieje sekcja .bss, która dosyć często popularna jest w linuksowych formatach plików z kodem, gdzie trzymane są nie zainicjalizowane dane, pod Windowsami ciężko na taką sekcję trafić, ja nigdy jej nie spotkałem. Podobnie .idata i .edata, które formalnie powinny zawierać dane o importach i eksportach, a najczęściej linker wrzuca je do .rdata. Sam jak tworzyłem DLL ręcznie w jakimś kodzie, to wszystko wrzuciłem do jednej sekcji .text głównie dlatego, bo było bardzo mało danych i kodu, a szkoda było zmarnować tyle przestrzeni adresowej i pamięci, potrzebowałem tego z jak najmniejszym narzutem.
To są tylko nazwy i teoretycznie nie powinno się za bardzo na nich polegać, gdyż kompilator i linker może zrobić co chcą, czyli wrzucić cokolwiek gdziekolwiek. Ważne jest to, aby dane sekcje posiadła odpowiednie atrybuty je opisujące (characteristics), by sekcja z kodem posiadała flagę zezwalającą wykonywanie kodu i odczyt danych, a sekcja z constami informującą ze to dane zainicjowane i dostęp tylko do odczytu itd. A także odpowiednie namiary w nagłówkach na directory. Loader sobie z tym już odpowiednio radzi, jak dane sekcje zinterpretować.
O możliwych standaryzowanych nazwach i sekcjach można poczytać w specyfikacji, gdzie przedstawiono długą ich listę. Wypada wspomnieć, że można tworzyć dowolne sekcje i trzymać w nich dowolne dane, niektórzy embedują tam jakieś zewnętrzne dane, choć jest to mało popularne, częściej wrzucając jakieś zewnętrzne rzeczy do zasobów. Wiele plików posiada również specjalne sekcje, chociażby kernel windowsowy (ntoskrnl) jak i linuksowy. Podobnie jest na przykład z binarkami (popularnie zwanymi wsadami) do mikrokontrolerów i różnych procesorków, gdzie czasami w sekcje rozdzielają poszczególne elementy, jak kod wynikowy trafiający do flash, dane do RAM i EEPROM, a nad wszystkim czuwa programator.
Mapowanie kodu do sekcji
Standardowo cała robotą związaną z mapowaniem kodu i danych do odpowiednich segmentów kodu, a następnie sekcji w pliku zajmuje się kompilator i linker. To właśnie dzięki przeprowadzanym optymalizacjom i trzymaniu się standardu (który jawnie nie porusza porblemu modelu pamięci) w prosty sposób kompilator może określić co i gdzie powinno się znaleźć. Oczywiście należy pamiętać, że język nie definiuje modelu pamięci, zależne jest to od platformy.
Ogólnie na platformie x86/64 w wielkim skrócie model ten prezentuje się następująco:
data global variables
static variables
code constant types
stack local variables
heap dynamically allocated space
W tym momencie nie jest to aż tak istotne, gdyż najbardziej interesuje mnie właściwe mapowanie kodu i zmiennych do odpowiednich segmentów oraz sekcji w czasie kompilowania i linkowania. Ale ta podstawowa wiedza pozwoli nieco łatwiej zrozumieć ten proces.
No to czas zrzucić jakimś kodem. Swój przykładowy i testowy kawałek kodu został zbudowany przy użyciu VC++2k13 (kompilator: 18.00.21005.1, linker: 12.00.21005.1).
[Niestety utraciłem fragmenty notatki i kodu, postaram się w przyszłości uzupełnić wpis…]
Komentarze (0)