ByteOrder - kolejność bajtów
• tech • 1926 słów • 10 minut czytania
Architektury współczesnych mikroprocesorów powszechnie używają dwóch różnych metod i konwencji przechowywania danych w pamięci, zwane “kolejnością bajtów” (byte order). Niektóre komputery umieszczają najbardziej znaczący bajt w słowie jako pierwszy (big-endian), a inne jako ostatni (little-endian).
Przez większość czasu, kolejność bajtów może być ignorowana, programista nie musi się martwić o to, jaki format jest używany, ale w niektórych sytuacjach staje się to ważne.
Kiedy implementujemy binarny format pliku, bibliotekę sieciową lub protokół, lub po prostu przesyłamy dane binarne miedzy innymi komputerami, musimy wziąć pod uwagę kwestie związane z uporządkowaniem bajtów.
Niestety nie istnieją żadne standardowe biblioteki, ani przenośne funkcje pozwalające w prosty i przenośny sposób operować na endianowości i konwersji między typami uporządkowania bajtów. Między innymi dlatego pokusiłem się o stworzenie biblioteki ByteOrder (ale o niej trochę później).
Kolejność bajtów
Nie będę przedstawiał tutaj szczegółów teoretycznych na temat konwencji kolejności bajtów, ani tłumaczył co, jak, i dlaczego - wszystko można znaleźć w sieci. W skrócie, jak napisałem we wstępie, obie konwencje różnią się uporządkowaniem bajtów, a dokładnie kolejnością w jakiej zapisywany jest najbardziej znaczący bajt w słowie. Szczegóły przedstawiają poniższe rysunki (dzięki uprzejmości Wikipedii):
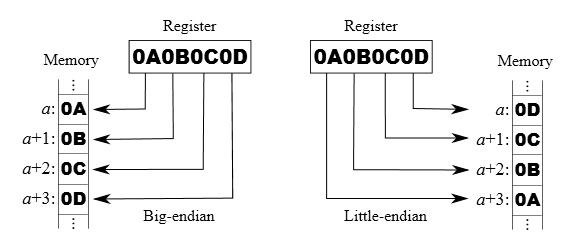
Jak wszyscy pewnie wiedzą, sieciowa kolejność bajtów (network byte order) to nic innego jak big-endian. Implementując protokół sieciowy, powinniśmy trzymać się właśnie tej konwencji.
Wykrywanie konwencji uporządkowania bajtów
Wykrywanie używanie przez system (host) konwencji zapisu danych można dokonać na dwa sposoby. Jednym z nich jest dedykacja w czasie kompilacji, a drugi w czasie działania.
Compile-time
Determinacja konwencji porządkowania bajtów w czasie kompilacji jest jedną z najpopularniejszych metod. Dokonać jej można na podstawie definiowanych przez systemowe nagłówki odpowiednich makr, lub bazując na pewnych stałych (makrach) określających platformę i system operacyjny.
Większość nowoczesnych systemów udostępnia makra “zawierające” informacje o konwencji uporządkowania bajtów używanych przez system. W systemach *nix, nagłówki systemowe zawierają odpowiednie definicje, na przykład linuksowy endian.h: __BYTE_ORDER, __LITTLE_ENDIAN, __BIG_ENDIAN.
Wykorzystać je można do testowania endianowości:
#if __BYTE_ORDER == __BIG_ENDIAN
#define I_AM_BIG_ENDIAN
#elif __BYTE_ORDER == __LITTLE_ENDIAN
#define I_AM_LITTLE_ENDIAN
#else
#error unknown byte order
#endif
Niestety niektóre systemy, na przykład Windows nie zawierają takich informacji, wtedy na podstawie platformy można również wydedukować, jaka konwencje używa nasz system:
#if defined(__sparc__) || defined(__powerpc__) || \
defined(__ppc__) || defined(__hpux) || \
defined(__s390__)
#define I_AM_BIG_ENDIAN
#elif defined(__i386__) || defined(__alpha__) || \
defined(__ia64__) || defined(__x86_64__) || \
defined(__amd64__) || defined(__bfin__)
#define I_AM_LITTLE_ENDIAN
#else
#error unknown byte order
#endif
Run-time
Determinacja kolejności bajtów w czasie działania aplikacji jest bardzo prosta. Skupia się na zapisaniu znanej wartości do pamięci i odczytania jej pierwszego bajta. Zależnie od jego wartości można wywnioskować używaną przez system konwencje układania bajtów.
Funkcja wykonywująca to działanie mogłaby wyglądać następująco:
enum ByteOrderType {
BigEndian,
LittleEndian,
};
inline ByteOrderType ByteOrderTest() {
volatile short int x = 0x1234;
return *reinterpret_cast<volatile char*>(&x) == 0x12 ? BigEndian : LittleEndian;
}
Rzutowania, uznawanego przez niektórych za wstrętne, można pozbyć się stosując unie w roli zmiennej x.
Zamiana kolejności bajtów
Istnieje wiele różnych sposobów i metod implementacji mechanizmów zmiany porządku bajtów w liczbach i wartościach. Jedne wykorzystują możliwości oferowane przez procesory, będące optymalnymi i szybkimi operacjami, inne przesunięcia bitowe, albo rozwlekle i naiwne implementacje oparte na układaniu poszczególnych bajtów w pętli.
Przesunięcia bitowe
Najczęściej stosowaną na świecie metodą radzenia sobie ze zmianą uporządkowania bajtów jest wykorzystanie operacji przesunięć bitowych.
Dla 16/32/64-bitowej liczby n operacje takie można zapisać w poniższej postaci:
uint16_t bswap16(uint16_t x) {
return (((x & 0xff00) >> 8) |
((x & 0x00ff) << 8));
}
uint32_t bswap32(uint32_t x) {
return (((x & 0xff000000) >> 24) |
((x & 0x00ff0000) >> 8) |
((x & 0x0000ff00) << 8) |
((x & 0x000000ff) << 24));
}
uint64_t bswap64(uint64_t x) {
return (((x & 0xff00000000000000ull) >> 56) |
((x & 0x00ff000000000000ull) >> 40) |
((x & 0x0000ff0000000000ull) >> 24) |
((x & 0x000000ff00000000ull) >> 8) |
((x & 0x00000000ff000000ull) << 8) |
((x & 0x0000000000ff0000ull) << 24) |
((x & 0x000000000000ff00ull) << 40) |
((x & 0x00000000000000ffull) << 56));
}
Przełożenie poszczególnych operacji bitowych na asembler w stosunku 1:1 da w rezultacie całkiem zgrabny kod, ale trochę rozwięzły i złożony. Po zastosowaniu optymalizacji, kod ten trochę się uprości, zmniejszy o średnio około 30% operacji. Postać taka, bazując na kodzie wygenerowanym przez VC2k12, mogłaby wyglądać następująco (pomijając ramki stosu i inne takie):
bswap16 proc
movzx edx, cx
movzx eax, dl
shr edx, 8
shl eax, 8
or eax, edx
ret 0
bswap16 endp
bswap32 proc
mov eax, ecx
mov edx, ecx
shl edx, 16
and eax, 0000ff00h
or eax, edx
mov edx, ecx
shr ecx, 16
and edx, 00ff0000h
shl eax, 8
or edx, ecx
shr edx, 8
or eax, edx
ret 0
bswap32 endp
bswap64 proc
mov r8, rcx
mov r9, rcx
mov rax, 00ff000000000000h
and r9, rax
mov rax, rcx
mov rdx, r8
shr rax, 16
and edx, 0000ff00h
or r9, rax
mov rax, rcx
mov rcx, 0000ff0000000000h
and rax, rcx
shr r9, 16
mov rcx, 000000ff00000000h
or r9, rax
mov rax, r8
and rax, rcx
shr r9, 16
mov rcx, r8
or r9, rax
mov rax, r8
and ecx, 00ff0000h
shl rax, 16
shr r9, 8
or rdx, rax
mov eax, ff000000h
and rax, r8
shl rdx, 16
or rdx, rcx
shl rdx, 16
or rax, rdx
shl rax, 8
or rax, r9
ret 0
bswap64 endp
Jak widać, złożoność takiej operacji nie jest wcale taka mała. Wraz z podwojeniem rozmiaru zmiennej ilość operacji dramatycznie wzrasta, co można zauważyć na 64-bitowej liczby. Być może lepszym rozwiązaniem byłoby potraktowanie 64-bitowej liczby jako dwie 32-bitowe i ich przekształcenie.
Na szczęście dotyczy to wartości konwertowanych w czasie działania programu, w jeśli wartość jest znana w czasie kompilacji, operacje przesunięć bitowych na znanych wartościach zostaną wyliczone przez kompilator, podstawiając w wyniku odpowiednia wartość.
Iteracyjne przemieszczenia
Czasami można spotkać implementacje funkcji konwertujących kolejność bajtów z wykorzystaniem pętli, gdzie każdy bajt zostaje “przeniesiony” w odpowiednie miejsce, co w skrócie odpowiada prostej operacji reverse.
Implementacja takiej funkcji może być podobna do poniższej:
void bswap(void* dest, const void* src, size_t len) {
const char* in = reinterpret_cast<const char*>(src);
char* out = reinterpret_cast<char*>(dest) + len;
for ( ; len > 0; len--)
*--out = *in++;
}
Rozwijając ją do asemblera otrzymujemy bardzo prostą formę:
bswap proc
; dest = eax
; src = ebx
; len = ecx
test ecx, ecx
je short end@bswap
lea eax, dword ptr [eax+ecx]
loop@bswap:
mov cl, byte ptr [ebx]
lea eax, dword ptr [eax-1]
lea ebx, dword ptr [ebx+1]
mov byte ptr [eax], cl
dec ecx
jne short loop@bswap
end@bswap:
ret 0
bswap endp
Oczywiście, zależnie od kompilatora i jego optymalizacji, a także rozmiaru danych, w wyniku możemy otrzymać całkiem inny, nijak niepodobny kod wynikowy, wraz z rozwinięciem pętli włącznie.
xchg, bswap, sse
Współczesne procesory posiadają pewne ciekawe rozkazy, których wykorzystanie może przyspieszyć i uprościć kod związany z odwracaniem kolejności bajtów.
Instrukcja xchg pozwala na konwersje ułożenia bajtów w 16-bitowych danych (rejestrach i pamięci):
xchg al, ah
Dla 32/64-bitowych liczb znajdujących się w rejestrze (tylko) można skorzystać, dostępnej od 486, instrukcji bswap, która “swapuje” bajty w danych 32/64-bitowych (zależnie od platformy):
bswap eax
Nie istnieją żadne instrukcje operujące na 128-bitowych danych, ale wraz z rozszerzeniami SSE2 i SSE3 doszły różne ciekawe instrukcje jak PSHUFD i PSHUFB, które mogą nam pomóc zaimplementować wydajne odwracanie bajtów w rejestrach xmm (128 bity).
Intrinsics
Najpopularniejsze kompilatory zawierają w sobie ciekawe rozszerzenia i wbudowane polecenia intrinsics, które mogą pomóc nam zamienić bajty, i to w najbardziej optymalny sposób jaki się da na danej platformie.
Visual C++ w nagłówku intrin.h definiuje funkcje:
unsigned short _byteswap_ushort(unsigned short val);
unsigned long _byteswap_ulong (unsigned long val);
unsigned __int64 _byteswap_uint64(unsigned __int64 val);
GCC posiada swoje odpowiedniki:
int16_t __builtin_bswap64(int16_t x);
int32_t __builtin_bswap32(int32_t x);
int64_t __builtin_bswap64(int64_t x);
Służą one do zmiany kolejności bajtów w kolejno 16/32/64-bitowych liczbach. Funkcje te są wbudowanymi instrukcje typu intrinsics, bezpośrednio rozwijanymi do kodu asemblera używającego, zależnie od platformy, operacji ror (16) i bswap (32/64), przez co są najszybszymi operacjami zmiany kolejności bajtów.
GNU C Library również zawiera optymalne definicje powyższych funkcji (nagłówek bits/byteswap.h), które dla wartości znanych w czasie kompilacji wyliczane są operacjami bazującym na przesunięciach bitowych, a dla pozostałych, o ile platforma na to pozwala, rozwijane do operacji wykorzystujących mnemonik ror* i bswap.
Biblioteka ByteOrder
Biblioteka ByteOrder, mieszcząca się w jednym nagłówku, dostarcza narzędzia i API, umożliwiające w wydajny, a zarazem prosty i przenośny sposób korzystać z elementów jakie opisano w tej notce.
Obecnie nie istnieje żaden standard określający wspólny interfejs funkcji związanych z obsługą endianowości. POSIX definiuje jedynie funkcje sieciowe do zmiany kolejności bajtów rodziny ntoh* i hton*. Mimo wszystko, większość systemów *nix posiada odpowiednie funkcje, często z przyjętą inną, acz zbliżoną konwencję nazewnictwa (Linux vs. BSD).
To właśnie brak standardowych i przenośnych narzędzi oraz potrzeba posiadania szybkich i wydajnych funkcji potrafiących konwertować dane pomiędzy konwencjami uporządkowania bajtów, stały się prekursorem do stworzenia tej biblioteki. Biblioteka ta może zostać doceniona w czasie cross-platformowych implementacji różnych bibliotek do obsługi formatu danych lub protokołu sieciowego, gdzie zwalnia nas z zajmowania się detalami związanymi z uporządkowaniem bajtów. Wykorzystanie możliwości systemu operacyjnego, platformy i kompilatora (wstawki asemblerowe, wbudowane instrukcje intrinsics i rozszerzenia kompilatora) przez definicje zawarte w nagłówku biblioteki ByteOrder, zapewniają najbardziej optymalne rozwiązania. Co szczególnie może być doceniane w implementacjach krytycznych elementów systemu.
Wykrywanie konwencji uporządkowania bajtów
Biblioteka dostarcza mechanizmy determinacji używanej przez hosta (platformę) konwencji uporządkowania bajtów. Podobnie jak to opisano wyżej w notce, dostępne są narzędzia działające w czasie kompilacji jak i działania programu.
Makra BYTE_ORDER i BYTE_ORDER_NAME dostarczają niezbędne informacje o używanej przez system konwencji w czasie kompilacji, a funkcje ByteOrderTest i ByteOrderName, są run-time-owymi odpowiednikami .
Swapowanie bajtów
Biblioteka definiuje wydajne funkcje służące do zmiany porządku bajtów liczbach 16/32/64-bitowych:
uintNN_t bswapNN(uintNN_t n);
Konwersje uporządkowania bajtów
Funkcje dostarczane przez bibliotekę ułatwiają konwersje z/do konwencji używanej przez system hosta a big/little-endian:
uintNN_t htoleNN(uintNN_t n);
uintNN_t letohNN(uintNN_t n);
uintNN_t htobeNN(uintNN_t n);
uintNN_t betohNN(uintNN_t n);
Podobne funkcje dostępne są w systemach Linux i BSD, ale w ByteOrder podążano za OpenBSD-ową konwencją nazewnictwa tych funkcji.
Kopiowanie z konwersją uporządkowania bajtów
Dodatkowo biblioteka definiuje funkcje, za pomocą których można odczytach z strumienia wejściowego dane 16/32/64-bitowe wraz z konwersja z/do konwencji używanej przez system hosta a big/little-endian:
void htoleNNcpy(void* dest, const void* src);
void letohNNcpy(void* dest, const void* src);
void htobeNNcpy(void* dest, const void* src);
void betohNNcpy(void* dest, const void* src);
C++ template
Nie zabrakło także, definicji szablonowych funkcji C++ do szybkiej i łatwej konwersji dowolnego typu:
template<typename T> inline T htole(T n);
template<typename T> inline T letoh(T n);
template<typename T> inline T htobe(T n);
template<typename T> inline T betoh(T n);
Wybór implementacji odpowiedniej funkcji następuje na podstawie rozmiaru typu wydedukowanego przez kompilator w czasie kompilacji.
Dostępność
ByteOrder działa na popularnych platformach – systemach Unix i BSD, Linuksie, Windowsie i Macu. Powinna także, kompilować się bez żadnych problemów pod nowoczesnymi kompilatorami C i C++ (C99, C11, C++98, C++11).
Biblioteka ByteOrder dostępna jest na stronie projektu na projects.malcom.pl, jej źródła leżą w dedykowanym repo na moim GitHubie. Tam również można znaleźć pełną dokumentację oraz przykładowe użycie/wykorzystanie.
Rozpowszechniana jest na zasadach licencji MIT.
W ramach podsumowania
Przedstawione informacje powinny nieco rzucić światłem na problem kolejności bajtów, oraz na to, że z pozoru wydające się proste operacje konwersji wcale nie musza być takie proste i szybkie. A wykorzystanie specjalnych i dedykowanych narzędzi do tego celu może przyspieszyć takie operacje, które w wielu zastosowaniach mogą znajdować się w krytycznych elementach systemu.
Powstanie biblioteki ByteOrder powinno zwolnić nas z kłopotu zajmowania się problemem uporządkowania bajtów, a skupić się na implementacji rozwiązania podstawowego problemu. Bo przecież główne zastosowanie biblioteki ByteOrder to niezależne o platformy operacje “swapowania” bajtów w liczbach 16/32/64-bitowych, konwersji kolejności bajtów danych między używanym przez host porządkiem a big/little-endian.
W ramach ciekawej zabawy i eksperymentów, postaram się, być może wkrótce, przedstawić implementacje funkcji bswap operującej na rejestrach xmm i korzystające z rozszerzeń SSE.
Komentarze (1)
Dziękuję, super artykuł.