Gnuplot-ing danych z LogView
• tech • 1659 słów • 8 minut czytania
Zawsze, gdy nie udaje mi się szybko (w kilka minut) osiągnąć spodziewanego efektu przy wizualizacji za pomocą wykresów w Excelu, przeskakuję na gnuplot-a i od razu świat wydaje się być lepszym miejscem. Nie trzeba się denerwować ograniczeniami w dostosowywaniu wyglądu jaki i możliwości. Wystarczy kilka linijek kodu (skryptu) i można wyrenderować dokładnie taki wykres jaki chcemy…
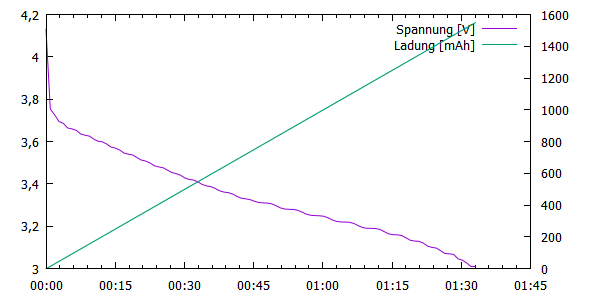
Gnuplot-a używałem z powodzeniem wiele razy w przeszłości, przy różnego rodzaju publikacjach, dokumentach czy pracach i zawsze byłem zadowolony z osiągniętych wyników. Tym razem, przy próbie zwizualizowania charakterystyk moich badanych ogniw Li-Ion, było podobnie. Chciałem na jednym wykresie przedstawić kilka charakterystyk, więc wymagane było kilka osi. Aby osiągnąć coś podobnego jak standardowo wykreśla LogView (poniższy rysunek).

Z tym, że na jednym wykresie chciałem mieć rozrysowane dane z wszystkich ogniw z całej paczki. W Excelu już nie było to takie proste lub wykonywalne. Ostatecznie jednak ograniczyłem się do tylko 2 danych - krzywa napięcia na ogniwie i oszacowanej pojemności w czasie.
Jakiekolwiek prace z gnuplotem warto rozpocząć od przejrzenia przykładowych wizualizacji oraz dokumentacji. To w zasadzie wystarcza, aby zacząć swoją pierwszą lub kolejną, po dłuższej przerwie, zabawę z tym narzędziem. W wielu przypadkach pierwszym krokiem jest próba narysowania wykresów ze swoich danych tabelarycznych bez żadnych dodatkowych ustawień i kombinacji, po prostu plotujemy:
plot "datafile.dat" with lines
Czasami jednak trzeba trochę bardziej się namęczyć i skonfigurować poinstruować plota o różnych swoich wymaganiach, zachciankach, danych, aby w wyniku otrzymać zadowalający i efektowny wykres.
Od którejś wersji plot, oprócz standardowych danych w formacie prostego tekstu z kolumnami oddzielonymi białymi znakami (często zapisanymi jako pliki .dat, bez problemu radzi sobie z także z popularnymi plikami CSV. Nie potrzeba więc żadnych konwersji i zabaw, bezpośrednio można plot-ować z danych CVS-a.
gnuplot> plot "Sanyo-1.csv"
^
Bad data on line 1 of file Sanyo-1.csv
Niestety tutaj mogą pojawić się różne problemy, zależne od pewnych konwencji przyjętych przy generowaniu pliku CSV. Fragment wyeksportowanych danych z LogView przedstawia się następująco:
Zeit [s];Spannung [V];Strom [A];Ladung [mAh];Leistung [W];Energie [Wh]; ...
0 ; 4,130; 0,080; 0,000; 0,330; 0,000; ...
1s ; 4,110; 0,220; 0,000; 0,904; 0,000; ...
2s ; 4,060; 0,360; 0,000; 1,462; 0,001; ...
4s ; 4,030; 0,510; 0,000; 2,055; 0,001; ...
5s ; 3,980; 0,650; 0,000; 2,587; 0,002; ...
7s ; 3,920; 0,790; 0,000; 3,097; 0,003; ...
8s ; 3,870; 0,930; 1,000; 3,599; 0,004; ...
10s ; 3,820; 1,000; 1,000; 3,820; 0,005; ...
...
Pierwsza linijka to tytuły kolumn, więc wystarczy zmusić gnuplota do ignorowania pierwszego wiersza lub go poprosić, aby tą pierwszą linię traktował jako etykiety:
set key autotitle columnhead
Inną opcją pozbycia się tego problemu jest jasne specyfikowanie za pomocą using kolumn z danymi do rysowania:
plot "Sanyo-1.csv" using 1:2
Co jednak w rzeczywistości tylko zignoruje problem, bo pierwsza linia nadal będzie traktowana jako dane do renderowania.

Choć udało się już coś narysować na wykresie to wyraźnie widać, że coś jednak poszło nie tak. Oba wykresy powinny być takie same, gdyż domyślnie gnuplot używa pierwszych dwóch kolumn z danymi. A ja otrzymałem zupełnie inne wykresy.
Problemem tutaj jest separator dla plików z danymi, którym domyślnie są białe znaki, a mój plik CSV standardowo oddziela kolumny za pomocą typowego ;.
set datafile separator ";"
Ustawienie poprawnego znaku separatora powinno załatwić sprawę. Od razu także przełączyłem się na linie, zamiast domyślnych punktów. Gnuplot pozwala na wiele sposobów renderować punkty danych, szczegóły można znaleźć w dokumentacji. Mi jak najbardziej pasują zwykłe linie, w końcu mają to być krzywe charakterystyk na wykresie, a nie jakieś inne prezentacje ;)
plot "Sanyo-1.csv" w l
Przy okazji, nie trzeba wpisywać pełnych nazw poleceń i komend, w większości przypadków wystarczą pierwsze literki.

Oprócz separatora danych warto także przyjrzeć się separatorowi dziesiętnemu. W danych jest nim , jak przystało na polskie (europejskie) warunki, niż spodziewany .. Skutkuje to przekłamaniami w danych i takim właśnie widocznym wykresem.
Najlepiej to sprawdzić i ewentualnie skorygować odpowiednie ustawienia locale dla aplikacji, choć te powinny być brane z ustawień systemowych. Bieżące ustawienia można podejrzeć za pomocą polecenia show.
gnuplot> show locale
gnuplot LC_CTYPE Polish_Poland.1250
gnuplot encoding default
gnuplot LC_TIME Polish_Poland.1250
gnuplot LC_NUMERIC C
Dla wartości numerycznych pozostaje format języka C, który należy ręcznie skorygować.
gnuplot> set decimal locale "Polish_Poland.1250"
decimal_sign in locale is ,
Format nazw lokalizacji jest systemowy, dlatego poza Windows-ami pewnie będzie to standardowe pl_PL.

Od razu widać, że chociaż częściowo interpretacje danych są poprawne. A problemem jest oś x, do której odwołuje się kolumna 1. A jak bliżej zerknąć na dane w niej zawarte:
0
1s
...
10s
...
59s
1m 00s
...
59m 59s
1h 00m 00s
...
1h 32m 51s
To widać wyraźnie, że przechowują bardziej ludzki format czasu zapisany w postaci stringów. Gnuplot zapewne stara się je zinterpretować jako liczby, co czyni aż do napotkania innego znaku, dlatego są one ograniczone do 60.
Jednak bez konwersji danych się nie obejdzie. Co prawda, mógłbym użyciu pipki przy czytaniu danych przez plota i w locie naprawiać ten syf, ale trzeba byłoby dużo napisać, szczególnie jak chcę renderowac kilka kolumn z jednego pliku i kilka plików na wykres.
plot "< awk -F, '{ ... }' data.csv" using 1:2
Od razu lepiej przetworzyć dane jakimś awk-iem lub perl-em. A że awka nie mam obecnie pod Windowsem, to chętnie skorzysta ze starego mojego ulubionego, poczciwego perla i magii jedno-linijkowców:
perl -ple "s/^\s(((\d+)h )?(\d+)m )?(\d+)s\s;/int(($3*3600)+($4*60)+$5).';'/e" data.csv
Ale żeby również nie namachać się na konsoli, to od razu walnąłem sobie skrypt konwertujący wszystkie CSV-ki w katalogu.
@echo off
setlocal enabledelayedexpansion
for %%i in (*.csv) do (
:: file.csv / file.dat
set fileCsv=%%~nxi
set fileDat=%%~ni.dat
echo Processing !fileCsv!
perl -ple "s/^\s(((\d+)h )?(\d+)m )?(\d+)s\s;/int(($3*3600)+($4*60)+$5).';'/e" "!fileCsv!" > "!fileDat!"
if %ERRORLEVEL% neq 0 (
echo Converting !fileDat! failed!
)
)
Mając już dane w sekundach, aby nie były one traktowane jako wartości liczbowe ale czasowe, warto ustawić odpowiednie formaty danych i etykiet dla osi X:
set xdata time
set timefmt "%s" # seconds since the Unix epoch
set format x "%H:%M" # pokazuj tylko godziny i minuty na osi x
No i gitara, wreszcie coś sensownego ukazuje wykres ;)

Wydaje mi się, że oś X trochę za bardzo jest ściśnięta, więc może lepiej będzie się prezentować rozdzielczość 15 minutowa? Nic trudnego!
set xtics 0, 60*15
Gdybym jednak chciał mieć oś X tylko w samych minutach, to niestety nie da się tego zrobić na danych czasowych. Specyfikator formatu M, prezentuje jedynie minuty w obrębie godziny. Ale jest na to sposób, traktowanie danych jako zwykłe liczbowe i przy plotowaniu dzielenie liczby sekund przez 60:
set xdata # wyłączenie poprzednich ustawień
set fotmat x # dotyczacych danych/etykiet osi x
plot "Sanyo-1.dat" u ($1/60):2 w l
Surowe dane z ładowarki zawierają pewne szumy i niedokładności pomiarowe, które skutkują postrzępioną krzywą na wykresie. Ja chciałbym mieć ładną, smukłą i wygładzoną linie na charakterystyce ogniw, zatem muszę je wygładzić. W gnuplocie mogę to zrobić na kilka sposobów.
Jednym z nich jest zastosowanie średniej kroczącej, można sobie napisać prostą funkcję do tego celu (patrz przykłady: running_avg.dem). Prócz takiej ręcznej metody, można skorzystać z wbudowanych metod służących wygładzaniu krzywych - smooth. Dostępne są 3 opcje: bezier, csplines i acsplines. Po szczegóły zapraszam do dokumentacji lub przykładów.
Spróbowałem porównać, jaka metoda dla moich danych będzie najlepsza.
plot "Sanyo-1.dat" using 1:2 with line title 'raw', \
"Sanyo-1.dat" using 1:2 with line smooth bezier title 'bezier', \
"Sanyo-1.dat" using 1:2 with line smooth csplines title 'csplines', \
"Sanyo-1.dat" using 1:2 with line smooth acsplines title 'acsplines'
Fragment wykresu w wielkim powiększeniu, aby można było dostrzec różnice.
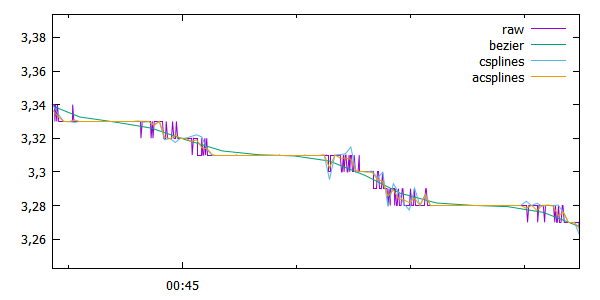
Zdecydowanie wybrałem metodę aproksymacji z krzywymi Beizera.
Teraz do wykresu mogę dorzucić drugą krzywą z pojemnością. Ale aby miało to sens i dobrze się prezentowały obie krzywe na jednym wykresie, gdzie znacznie różnią się skale, muszę dodać kolejna oś Y, najlepiej na prawej stronie.
set y2tics # pokaz tiki na osie y2
set ytics nomirror # ale bez mirrorow z y1
plot "Sanyo-1.dat" using 1:2 with line smooth bezier axes x1y1, \
"Sanyo-1.dat" using 1:4 with line axes x1y2
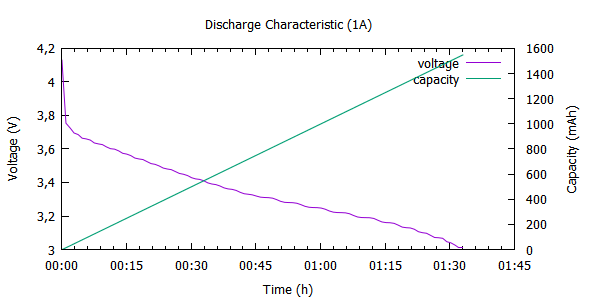
Nie wygląda to źle, ale wypadłaby dodać trochę warstwy opisowej dla osi i krzywych.
set title "Discharge Characteristic (1A)
set xlabel "Time (h)"
set ylabel "Voltage (V)"
set y2label "Capacity (mAh)"
plot "Sanyo-1.dat" using 1:2 w l smooth bezier axes x1y1 title "voltage", \
"Sanyo-1.dat" using 1:4 w l axes x1y2 title "capacity"
Teraz można zapuścić rendering wszystkich ogniw z paczki na wykres, ale aby nie powtarzać tych 2 linii dla każdego pliku z danymi 6-ciu ogniw, można użyć prostej pętli:
plot for [i=1:6] "Sanyo-".i.".dat" u 1:2 w l smooth bezier axes x1y1 t "vol".i, \
for [i=1:6] "Sanyo-".i.".dat" u 1:4 w l axes x1y2 t "cap".i
Niestety wyszło to wszystko trochę za bardzo upakowane.
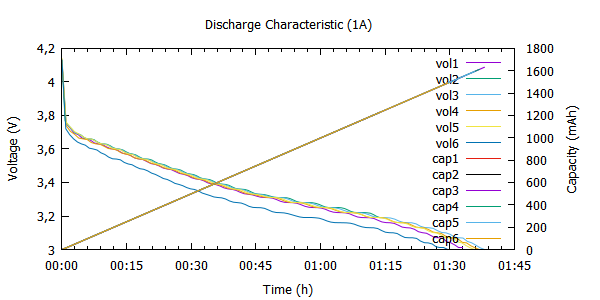
Docelowo jednak zrezygnowałem z pojemności i pozostaję tylko przy kreśleniu charakterystyki napięciowej ogniwa, wszakże czy krzywa pojemności jest mi tak bardzo potrzebna?
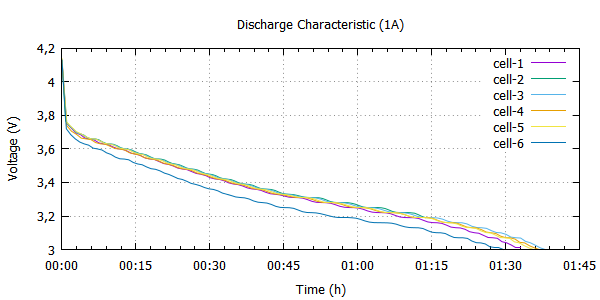
Ostateczna wersja skryptu używanego do wygenerowania powyższego wykresu:
set terminal wxt size 600, 300
set key autotitle columnhead
set datafile separator ";"
set decimal locale "Polish_Poland.1250"
set xdata time
set timefmt "%s"
set format x "%H:%M"
set xtics 0, 60*15
set grid
set title "Discharge Characteristic (1A)"
set xlabel "Time (h)"
set ylabel "Voltage (V)"
plot for [i=1:6] "Sanyo-".i.".dat" u 1:2 w l smooth bezier axes x1y1 t "cell-".i
Używam terminala typu wxt, czyli implementacji wxWidget-owej, dzięki czemu na żywo mogę jeszcze trochę pomanipulować wyglądem wykresu, rozmiarem etc. Waląc wprost z konsoli warto przełączyć się na bezpośrednie generowanie plików png. Jeśli dobrze kojarzę to wymaga to libgd, a nie jestem pewny czy akurat mam takowy pod Windą.
Ostatecznie wprowadziłem jeszcze inne zmiany. Typowe charakterystyki rozładowania w datasheetach są funkcją napięcia względem pojemności, dlatego takie sobie wygenerowałem na potrzeby mojego badania ogniw opisanego w poprzedniej notatce.
Gnu plot to bardzo potężne narzędzie z wielkimi możliwościami. Ja na swoje potrzeby korzystałem tylko najprostszych i najczęściej używanych ustawień, ale można zrobić naprawdę niezłe wizualizacje. Prócz oficjalnych przykładów i dokumentacji polecam także zerknąć na stronę Gnuplotting i Gnuplot tricks, gdzie można znaleźć fajne tricki związane z gnuplotem. Polecam również kolekcję galerii na wikimedia używanymi wizualizacjami z gnuplota w projekcie Wikipedii.
Bez ogródek mogę rzec, że gnuplot to jednak KillerApp do wizualizacji wszelakich danych ;)
Komentarze (0)